

Outline
The Neural Spectrogram
- The ASA problem can be clarified by means of a spectrogram, a visual representation of how the frequencies in a sound change over time. The horizontal axis represents time (just as in a musical score) and the vertical one, frequency. The amount of sound at each point of time, at each frequency is represented by the darkness at that point in the diagram. (It should be pointed out that most natural sounds are made up of many frequencies.)
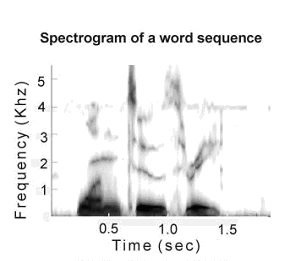
- Below, we have a spectrogram of the word sequence "One, two, three". I mention the spectrogram here because it represents a major part of the information that is extracted by the earlier-acting part of our auditory systems before it passes the information up to the main part of our brains. So the brain has this sort of information available to it. We might call it a "neural spectrogram". You would think that this might be sufficient for the brain to recognize the sounds. Indeed, the visual pattern shown in the spectrogram can actually be read by highly trained individuals, who can tell you the words that it represents. So the information contained there is sufficient for recognition.
The problem of mixtures
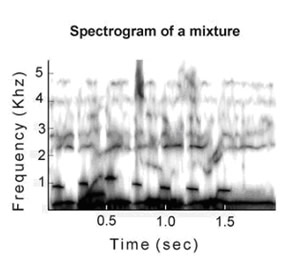
- However, the problem is not so simple. Remember that in many situations, several sounds may be occurring at the same time, or partially overlapped in time, and the acoustic information from all of them is mixed at the ears of a listener. So instead of the spectrogram shown above, we have a more complex one, like the one shown below.
This is a spectrogram of a mixture of (a) the spoken words "one, two, three," (b) singing "da-da-da," (c) whistling, (d) computer fan. (Bregman & Woszczyk, 2004, Figure 1. Reproduced with permission from A. K. Peters.)- It is as if the separate spectrograms of the individual sounds were laid on top of one another. In everyday situations, when sounds are mixed, this is the type of information that the brain must work with. It is faced with a puzzle that has two parts: (1) Which frequencies that are present at the same instant arose from the same sound? (2) How should the acoustic information be connected over time to form a mental representation of an extended event (like a word) or of a sequence of events (like a sentence)? The first problem is called simultaneous integration or perceptual fusion, and the second is called sequential integration.
Two kinds of grouping
Sequential integration
- Acoustic factors influencing sequential grouping
- While sequential integration is very complex, and interacts with perceptual fusion (simultaneous integration), most studies on the former topic have been carried out with sequences of simple sounds. One of the first observations was that in a very rapid sequence of sounds, say a tenth of a second per sound, a particular sound was not necessarily heard as falling in between the ones that came immediately before or after it. It could link up, instead, with ones that were a few steps away in the sequence provided that the linked sounds were very similar. The result was one or more perceived streams of sounds in which similar sounds were in the same stream.
- We have given the name auditory stream segregation to the phenomenon in which a single sequence of sounds breaks up into two or more parallel perceptual streams. These streams appear to be happening at the same time, and each is heard as a separate sequence of sounds, with its own melody and rhythm. Auditory stream segregation in a rapid sequence of sounds is sometimes called streaming.
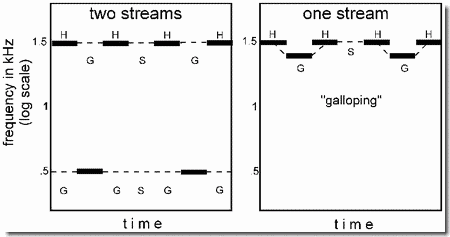
- Stream segregation can be demonstrated by the repeated alternation of high (H) and low (L) tones in a galloping rhythm: HLH-HLH-HLH... (where the dash represents a silence equal in duration to a tone). We start with a sequence in which the H and L tones are far apart in frequency (Panel a) and gradually speed it up. At slow speeds we hear the galloping rhythm formed of the H and L tones; but as the sequence speeds up, we perceive two separate streams of sound, a higher stream containing only the H tones, and a lower one containing only the L tones. The galloping rhythm disappears and is replaced by separate regular repetitions of a single tone, the L in the low stream, and the H in the high stream (as seen below in panel a, on the left). However, if the H and L tones are close together in frequency (Panel b), then even at high speeds, the galloping rhythm is still perceived and there is no segregation into high and low streams.
Here is a demonstration
In this demonstration, separate auditory streams are constructed by the brain by linking tones on the basis of their similarity. I am not saying that being close in time has no affect on the grouping of tones. It does: tones that are closer together in time are more likely to be assigned by the brain to the same perceptual stream. But temporal proximity is only one of many factors. While it is true that the galloping pattern will form separate streams if the two tones are different in frequency as in the previous example, they can also be different on other ways, for example, in timbre (Demonstration #10), in loudness, or in spatial origin (Demonstration #38). They are also more likely to be included in the same auditory stream if there is a smooth transition from each sound to the next than if the transitions are abrupt (Demonstration #12).- Perceptual effects of sequential grouping
- When the two streams form as in the example of the "galloping" sequence of tones, two things are immediately apparent. The first is that each stream has its own melody, and the overall melody formed by all the tones in the total sequence is lost. In the case where there are only two tones, a high and a low, the notion of a melody is overly simple. However, we can take a more complicated case in which there is a repeating cycle of three high tones of different frequencies (H1, H2, and H3) and three low ones (L1, L2, and L3). High and low tones are interleaved, for example the order could be H1, L3, H2, L2, H3, L1, repeated over and over. If they all fall into a single unified stream, we hear an irregular up-and-down melody. But if the high and low streams are perceptually segregated, we hear two streams. The high one is the repeated cycle H1-H2-H3..., , and the low one is L3-L2-L1.... (In these letter sequences the hyphens represent "silences" that take the place of the tones that were assigned to the other stream). Each of the segregated streams is a regular ascending or descending sequence of pitches. So the segregation has created separate melodies. Going back to the galloping sequence HLH-HLH-HLH-... that I described earlier, the breakup into two streams forms a new rhythm. The high stream is H-H-H-, etc, and the low one is L-L-L-..., etc. The high tones are twice as fast as the low ones. So we see that the rhythm is changed by segregation.
- We can summarize all this by the statement that melodies and rhythms are computed only within streams, and not across streams, by the ASA system. So stream segregation changes the perception of both melody and rhythm.
- Another result of streaming that is easy to observe is that the high and low tones don't seem to be exactly interleaved in time any more. In fact we seem to be unaware of the exact sequence of high and low tones. About half of a group of untrained listeners who heard only a sequence in which three high and three low tones were rapid and well separated in frequency, and hence heard in different "streams", thought that the order of tones was three high ones followed by three low ones.
- There are other consequences of sequential grouping, but if you want to know about them, you will have to read my book, Auditory Scene Analysis.
Simultaneous integration (perceptual fusion)
- Acoustic factors influencing simultaneous integration
- When many frequencies are heard at the same time, the ASA system must decide whether they are components of the same sound, or of two or more sounds. If they are all assigned to the same sound, they will be used together to build the perceived properties of that sound. If they are allocated to different sounds, the properties of each of these sounds will be built from the frequencies allotted to it.
- The factors used in making this perceptual allocation are based on the probable relations between frequency components when they are all from the same sound. For example, they tend to start and stop together, to rise and fall in intensity together, to be near one another in frequency, to come from the same location in space, and to belong to the same harmonic series. [A harmonic series of frequencies means that all of the frequencies are multiples of a "base" value. For example, the frequencies 200 Hz, 300 Hz, and 400 Hz are part of the same harmonic series, multiples of 100 Hz.]. So if some of the frequency components ("partials") present at a given moment exhibit any of these relations, they tend to be allocated to the same sound.
- Perceptual effects of simultaneous grouping
- The perceived pitches, loudness, timbres and even locations in space can be influenced by how the partials are grouped. Are we hearing a single sound or is it made up of two or more, with their own pitches? Are we hearing one loud sound or two softer ones superimposed? Are we hearing a single sound with a rich timbre, or two simpler ones? Are we hearing a single sound straight ahead of us or two sounds, one on the left and the other on the right? The simultaneous grouping gives us the answer to these questions.
Interaction between sequential and simultaneous grouping
- Competition for a frequency component (a partial)
- So far I have described sequential and simultaneous grouping as if they were two independent processes. But that is not true. They interact in partitioning the complex and changing mixture of frequencies that reaches our ears. In some cases they may compete. For example a given partial (D) could either be part of a series of sounds, A, B, C, that has led up to, and is continuing within, the current mixture, or else part of a new sound, D1, that has just entered the mixture. This decision will be based on whether D is a better fit with A, B, and C, or with the other partials of D1.
- The "old-plus-new" strategy
- This strategy, carried out by the ASA system, affects the grouping of partials. It works as follows: When a spectrum gets more complex, or parts of it get more intense, try to interpret it as a continuing (old) spectrum to which new components have been added. If it can be interpreted in this way, the ASA system can guess what parts of the current sound are the continuation of an old one. Then it can subtract these "old" components out of the mixture and get a clearer picture of what the newly added partials are. For this reason the onset of a new sound is a very crucial point at which its properties become more obvious, because its onset triggers this decomposition of the set of components present at that time. The onset of the sound is very important for another reason. The ASA system can determine which partials started at the same time, and use this relation to group them.
